관계형 데이터베이스의 부족한 점
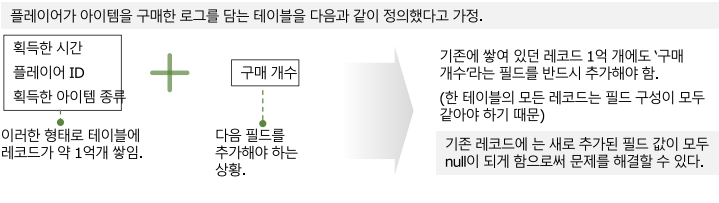
- 기존 테이블에 레코드 1억 개가 이미 들어있다고 가정
- 필드 하나를 추가하면 데이터베이스 엔진은 기존에 있는 레코드 1억 개 전체에 필드를 추가해야 함
- 프로그램 구조가 복잡해질수록 테이블 구조도 변경, 유지보수하면서 점점 힘들어짐
데이터베이스의 수직분산과 수평분산
- 데이터베이스의 수직 분산: 여러 테이블을 각각 여러 데이터베이스 컴퓨터에 나눔
- 데이터베이스의 수평 분산: 테이블 하나가 레코드를 1억 개 가졌다고 가정하고 데이터베이스 컴퓨터가 100대 주어졌다면, 각 컴퓨터에 데이터베이스를 설치하고 1억을 100으로 나눈 수인 100만 개씩 레코드를 분배, 이렇게 수평으로 분산된 데이터베이스에서는 각 컴퓨터가 큰 테이블 1개를 조각조각 가진 셈으로, 이를 샤드라고 함
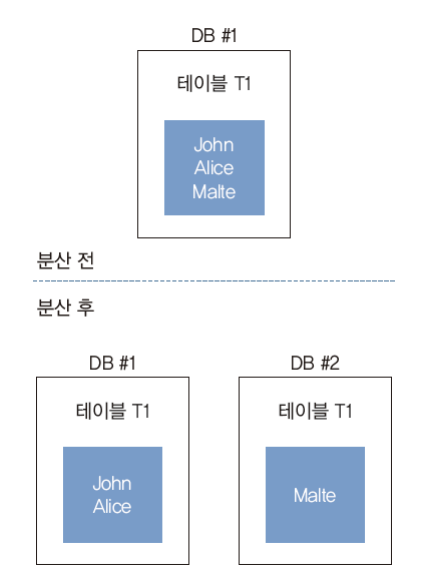
이 상태에서 데이터베이스를 액세스하려면
- John의 레코드를 얻고자 할 때는 먼저 John이 어느 샤드에 있는지 파악해야 함
- 해시 함수 사용: John이라는 문자열을 입력 값으로 하여 해시 함수를 실행, 연산 후 얻은 정수 값을 샤드 넘버로 사용
- 로케이터 DB 사용: John이 어느 샤드에 저장되었는지를 담고 있는 별도의 테이블에 액세스하여 John이 어느 샤드에 있는지 파악
해당 샤드에 데이터베이스 질의를 실행하기
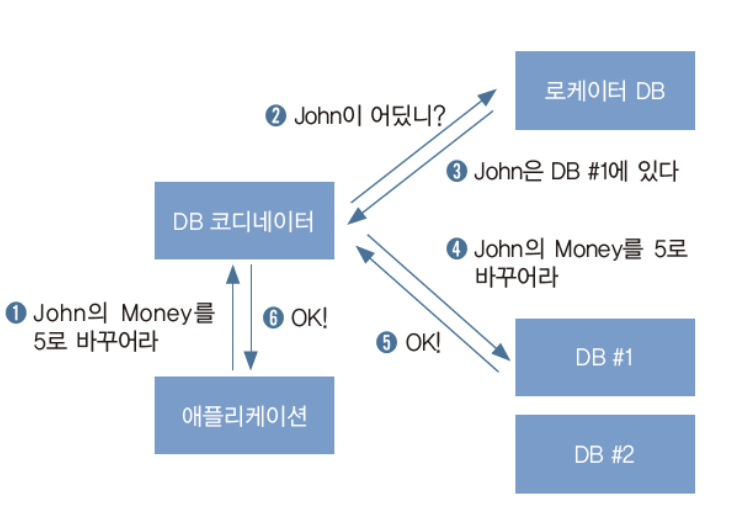
- 앱(게임 서버)이 데이터베이스에 질의를 던짐
- 데이터베이스 질의를 수행하는 코디네이터(coordinator)는 질의에 관련된 레코드가 있는 위치를 어떤 데이터베이스에 물음
- 해당 샤드 위치를 파악
- 해당 샤드에서 레코드 액세스를 처리
- 결과를 받음
- 결과를 받음
분산 락
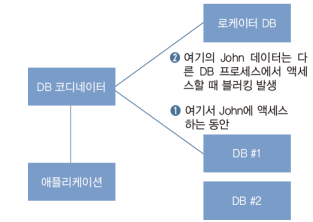
: 기기 둘 이상에 걸쳐 저장된 데이터를 액세스하는 동안 다른 스레드나 프로세스에서 액세스를 블로킹 시켜주는 것
기기 두 대 이상에 걸쳐 발견되어야 하는 데이터는 내부적으로 분산 락으로 보호되면서 액세스 되고, 이렇게 함으로써 일관성을 지킬 수 있음
일관성을 중요시 할 때의 처리 과정)
일관성을 중요시하지 않을 때의 처리 과정)

- 샤드에 든 레코드를 액세스하는 동안 관련된 다른 기기에서 락의 강도를 낮추면
- 락이 그만큼 줄기 때문에 수평 분산의 효과를 제대로 볼 수 있음
- 액세스하는 데이터가 항상 같은 결과를 입출력하지 않는 결과가 발생할 수 있음
- "더 이상 관계형 데이터베이스로서 역할을 하지 못함"
장애 극복(fail over) - 레코드의 상시 백업
- 이중화 혹은 다중화(redundancy): 같은 데이터가 DB 1과 DB 2에 모두 있게 하는 것
- DB 1을 액세스하다가 DB 1이 죽으면 DB 2가 DB 1대신 액세스를 받아 처리함
- 이때 DB 1을 액티브 또는 마스터 라고 하며, DB 2를 패시브 또는 슬레이브라고 함
- 이렇게 구성된 데이터베이스는 한쪽이 죽더라도 나머지가 대체 역할을 하기 때문에 항상 이용 가능한 상태가 됨
- 즉, 고가용성을 만족시킴
데이터 일관성
- 데이터를 변경할 때 액티브와 패시브를 모두 변경한 후에야 '처리 완료'를 선언하고, 그때까지 질의 실행 결과는 블로킹 됨
- 게임 서버가 질의 구문을 수행할 때는 1, 4 뿐만 아니라 2, 3이 끝날 때까지 대기
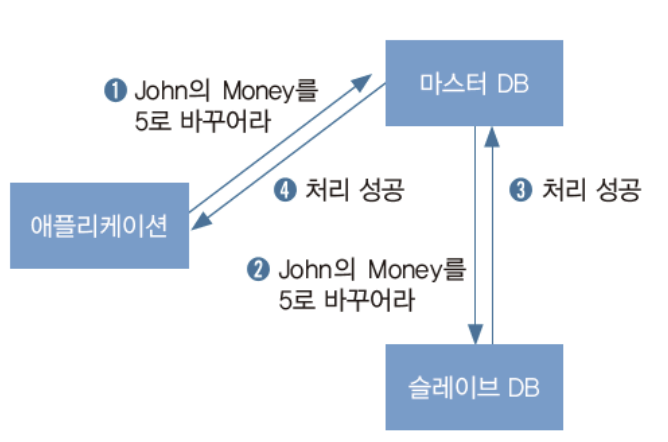
고가용성을 유지하면서 데이터베이스 처리 속도를 유지하려면
: 슬레이브가 없을 때처럼 속도가 잘 나오게 하려면, 슬레이브의 변경 전파 과정을 건너 뛰고 바로 게임 서버에 응답함
- 게임 서버가 마스터 DB에 변경하는 질의를 보냄
- 마스터 DB는 변경 요청을 바로 처리하고 결과를 반환
- 마스터 DB는 슬레이브 DB에 변경된 것을 알려줌, 슬레이브 DB는 변경 사항을 자기 자신에게 적용함
- 최신이 아닌 데이터인 스테일 데이터(stale data)를 가져오는 문제가 있음
관계형 데이터베이스는 ACID(원자성, 일관성, 고립성, 지속성)를 추구하는 것이 원칙
ACID 중에서 C(일관성)와 I(고립성)를 어느 정도 포기하면 '만족스러운 수준'의 스케일 아웃(기기를 많이 두어 문제를 해결할 수 있음)과 고가용성을 확보할 수 있음
BASE(Basically Available), '기본적으로 가용성'
- "데이터 상태가 유연함"
- 그들의 일관성을 결과적 일관성이라고 함
NoSQL
- ACID 대신 BASE를 지향
- 일관성을 일부 희생하더라도 높은 확장성과 고가용성을 실현
- 탈 테이블 구조의 유연한 저장방식을 이용하여 더 효율적인 프로그래밍을 추구
MongoDB에서 다루는 데이터 집합 관계와 관계형 데이터베이스(RDBMS)의 집합관계의 차이
- RDBMS에서 DB 인스턴스라고 부르는 것은 MongoDB에서도 똑같이 부름
- RDBMS의 DB 인스턴스 안에는 테이블이 있음, MongoDB의 DB 인스턴스 안에는 컬렉션이 있음
- RDBMS의 테이블 안에는 레코드가 있음, MongoDB에서는 컬렉션 안에 레코드 대신 document가 들어감

MongoDB로 샤딩을 구성하는 방법
: MongoDB 샤드 클러스터를 구성할 수 있음
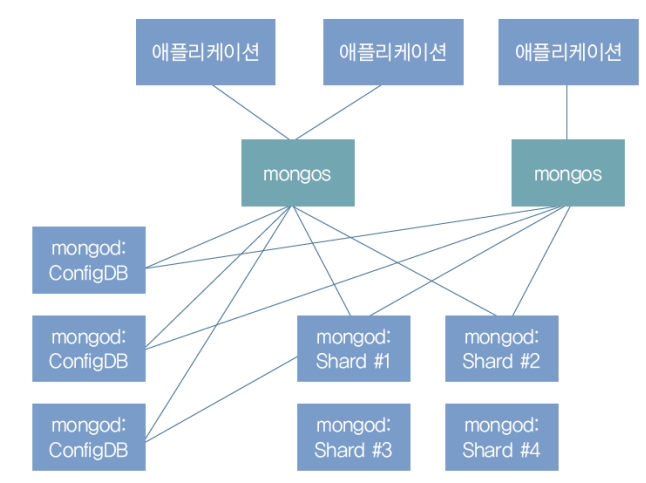
- mongos는 App, 즉 서버에서 명령을 받음
- 적절한 샤드로 명령을 보내 결과를 받는 중계자 역할을 함
- ConfigDB는 이러한 MongoDB 샤드 클러스터에 관한 정보를 담고 있음
- 기존 MongoDB 데이터베이스 서버, 즉 mongod.exe가 그대로 사용됨
- 각 샤드는 샤드 키로 구분되는 도큐먼트를 분배해서 가짐
- 마찬가지로 mongod.exe가 그대로 사용됨
게임 서버에서 MongoDB 명령 실행


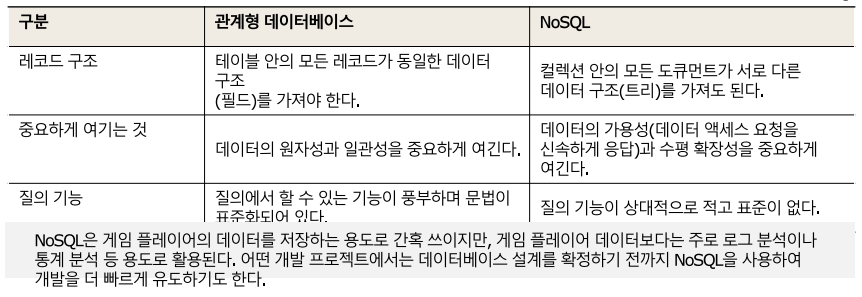
NoSQL과 관계형 데이터베이스의 차이
'Old > 복습' 카테고리의 다른 글
| C++ - 범위 기반 for문 (1) | 2024.01.03 |
|---|---|
| C++ - 생성자와 소멸자 (0) | 2023.12.27 |
| 운영체제 - Call Stack (0) | 2023.12.27 |
| 운영체제 - Thread (0) | 2023.12.27 |
| 게임 서버 - 데이터베이스 기초 (2) | 2023.08.01 |


